How I Scraped LinkedIn Data Using Selenium and Beautiful Soup
Mentor: Sining Chen
LinkedIn is a social network designed for professional networking and is greatly employment-oriented. Its website and applications include hundreds of millions of professional user profiles as well as job postings.

In order to gain insight into the job market as demonstrated by LinkedIn, we used web scraping tools written in Python: Selenium and Beautiful Soup. This story covers how you may install a selenium webdriver and Beautiful Soup onto your computer with pip in order to access the information we see on LinkedIn. Especially by using a webpage’s source code, we created automated functions like inputting text in a search box, clicking buttons, and scraping text. To do this, we had to overcome a few challenges including differentiating between Selenium and Beautiful Soup, locating the elements we needed to access, and avoiding the errors brought by the messaging pop-up.
We also visualized the trends shown by our data. Our graphs are displayed in our other story, which is linked below: https://medium.com/@sophie14159/linkedin-job-trends-2dd64f1d4541
Selenium
Selenium Python provides an API that allows you to access webdrivers including Firefox, Internet Explorer, and Chrome, which will be demonstrated later on.
Beautiful Soup
Beautiful Soup is a python library that allows us to scrape information from web pages by accessing their source code. This uses an HTML or XML parser.
More information can be found with other resources at the end of this story.
Installations
In order to scrape from a webpage like those in LinkedIn, we must install selenium, Beautiful Soup and a webdriver.
- Installing pip
I needed to install both pip and selenium onto my laptop, and I did this using the Command Prompt. I first installed pip.

Note: Since I already had pip downloaded, it was uninstalled and reinstalled to have the newest version. Then, to access pip and install selenium, I needed to use “pip install selenium”. However, as the warning suggests, I also needed to change the path with “cd” to access pip.
2. Installing Selenium and Beautiful Soup
With pip successfully installed and able to be accessed, I simply used the commands “pip install selenium” and “pip install bs4”. Thus, Selenium and Beautiful Soup were successfully installed as well. We are now able to use them in our python scripts.
3. Download webdriver
In my case, I decided to use a chromedriver although, as mentioned before, Selenium is not limited to Chrome. Depending on which version of Chrome I had, I used the following site to download the chromedriver: https://chromedriver.chromium.org/downloads.
Note: If you are unsure which version of chrome you have, you may follow the instructions here.
With Selenium, Beautiful Soup, and a webdriver set up, we are ready to write our code!
Python Script
#import chrome webdriver
from selenium import webdriverbrowser = webdriver.Chrome('chromedriver_win32/chromedriver.exe')
In the code above, we imported the chromedriver, which will now allow us to access webpages from the chrome browser. Next, I logged into my LinkedIn account to access those webpages.
#Open login page
browser.get('https://www.linkedin.com/login?fromSignIn=true&trk=guest_homepage-basic_nav-header-signin')
#Enter login info:
elementID = browser.find_element_by_id('username')
elementID.send_keys(username)
elementID = browser.find_element_by_id('password')
elementID.send_keys(password)#Note: replace the keys "username" and "password" with your LinkedIn login infoelementID.submit()
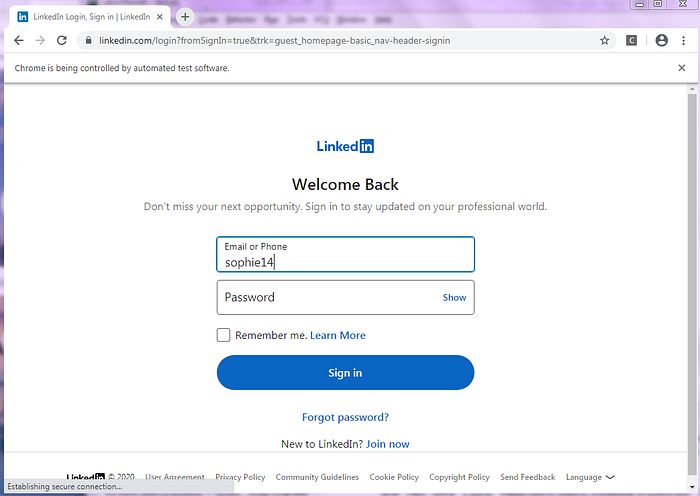
An automatic webpage should open and the program will automatically input your username and password as you had set up in the code.
Something to keep in mind is that, since you are using your own LinkedIn account, the webpages and information you can access from LinkedIn are limited to what your profile can access. For example, specific users you are not connected with may not be visible to you.
Successfully logged in, we are now able to perform many functions, a few of which that I have used are listed below:
1. Inputting in a search box
#Go to webpage
browser.get('https://www.linkedin.com/jobs/?showJobAlertsModal=false')#Find search box
jobID = browser.find_element_by_class_name('jobs-search-box__text-input')#Send input
jobID.send_keys(job)
In the instance above, I accessed the page where I am able to search for jobs. The element that I needed the browser to find was the search box. I found the class name by right-clicking on the page and going into “inspect” which shows me the source code of any webpage.

In fact, making use of the source code was the more important key to performing the functions in my code. By clicking the arrow on the top left corner of the source code window, I could see the code of any element I clicked on the LinkedIn page. I would then insert the class name into my python code to access it.
2. Clicking a button
Clicking a button can be submitting the input you entered in the search box above but is definitely not limited to that. For my own purposes, I needed to click a button to open the list of filters that were applied to a job search.

This is a simple, two-step, process:
- Find the element and
- Perform the click method on the element
browser.find_element_by_class_name("search-s-facet__button").click()I found the element class name through the source code, as explained in the previous function, then applied the click method. I wrote this code in one line but it can also be done in two with a variable:
#These two lines of code are not clicking the same button as the previous instancesearch = browser.find_element_by_class_name('jobs-search-box__submit-button')
search.click()
3. Scraping text
In the code after the image, I tried to obtain the number of job postings that resulted from a search for a specific type of career. This number was first stripped as a string, so I had converted it into an integer, as well.

#Get page source code
src = browser.page_source
soup = BeautifulSoup(src, 'lxml')#Strip text from source code
results = soup.find('small', {'class': 'display-flex t-12 t-black--light t-normal'}).get_text().strip().split()[0]
results = int(results.replace(',', ''))
Errors and Solutions
Selenium and Beautiful Soup can work together to perform many functions that are definitely not limited to what I have used above. However, I would like to address a few errors I have run into while writing my own code and also explain my solutions.
1. Selenium v.s. Beautiful Soup
Since my code made use of both Selenium and Beautiful Soup, I often confused which one I needed to use depending on my purposes. I once tried to find and click an element by searching for it in the html code before realizing that I was trying to perform a Selenium function using Beautiful Soup!
Although the two work together, Beautiful Soup allowed me to scrape the data I could access on LinkedIn. Meanwhile, Selenium is the tool I used to automate the process of accessing those webpages and elements on the website.
2. Unable to locate element
This was perhaps the most frustrating error as there are elements in the source code that my code could not seem to access.
The following is a block of code that helped me fix this problem:
last_height = browser.execute_script('return document.body.scrollHeight')
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(SCROLL_PAUSE_TIME)
new_height = browser.execute_script('return document.body.scrollHeight')
last_height = new_heightThe block of code above acts as a page loader that allowed me to reach more of the source code to find the elements I needed. For example, when you first load a page, you cannot see much of the website until you scroll down. The code above allows you to automate that “scrolling down” action.
A link to the YouTube channel that introduced me to this code is linked at the end of this story along with other resources.
3. Messaging pop-up
One of the first issues I ran into was the way my messages would pop-up and essentially block a chunk of the webpage that I wanted to be able to see.

This seemed to be an automatic function in LinkedIn so I needed a way around it. If I were manually using LinkedIn, I would simply click the messaging tab once and the pop-up would minimize itself. I needed to perform this action in my code.
My solution below checks to see if the pop-up has already been minimized, in which case it would not block the other elements on the page. If my code cannot find the minimized messages then I look for the case where it which it is in fact a pop-up and click it away.
#Import exception check
from selenium.common.exceptions import NoSuchElementExceptiontry:
if browser.find_element_by_class_name('msg-overlay-list-bubble--is-minimized') is not None:
pass
except NoSuchElementException:
try:
if browser.find_element_by_class_name('msg-overlay-bubble-header') is not None:
browser.find_element_by_class_name('msg-overlay-bubble-
header').click()
except NoSuchElementException:
pass
Conclusion
Selenium and Beautiful Soup allows us to perform many different functions including scraping the data I obtained from LinkedIn. Using the data I was able to collect using the functions in this story, I was able to obtain the data necessary to generate graphs reflecting the job market as suggested by LinkedIn.
Resources:
Selenium: https://selenium-python.readthedocs.io/
Beautiful Soup: https://pypi.org/project/beautifulsoup4/
Relevant YouTube Channel: https://www.youtube.com/channel/UCTiWgVtEGSY4cuduJbMPblA

